July 14, 2023
4 Internet Creeping Versions Web Scratching With Python, Second Version Book
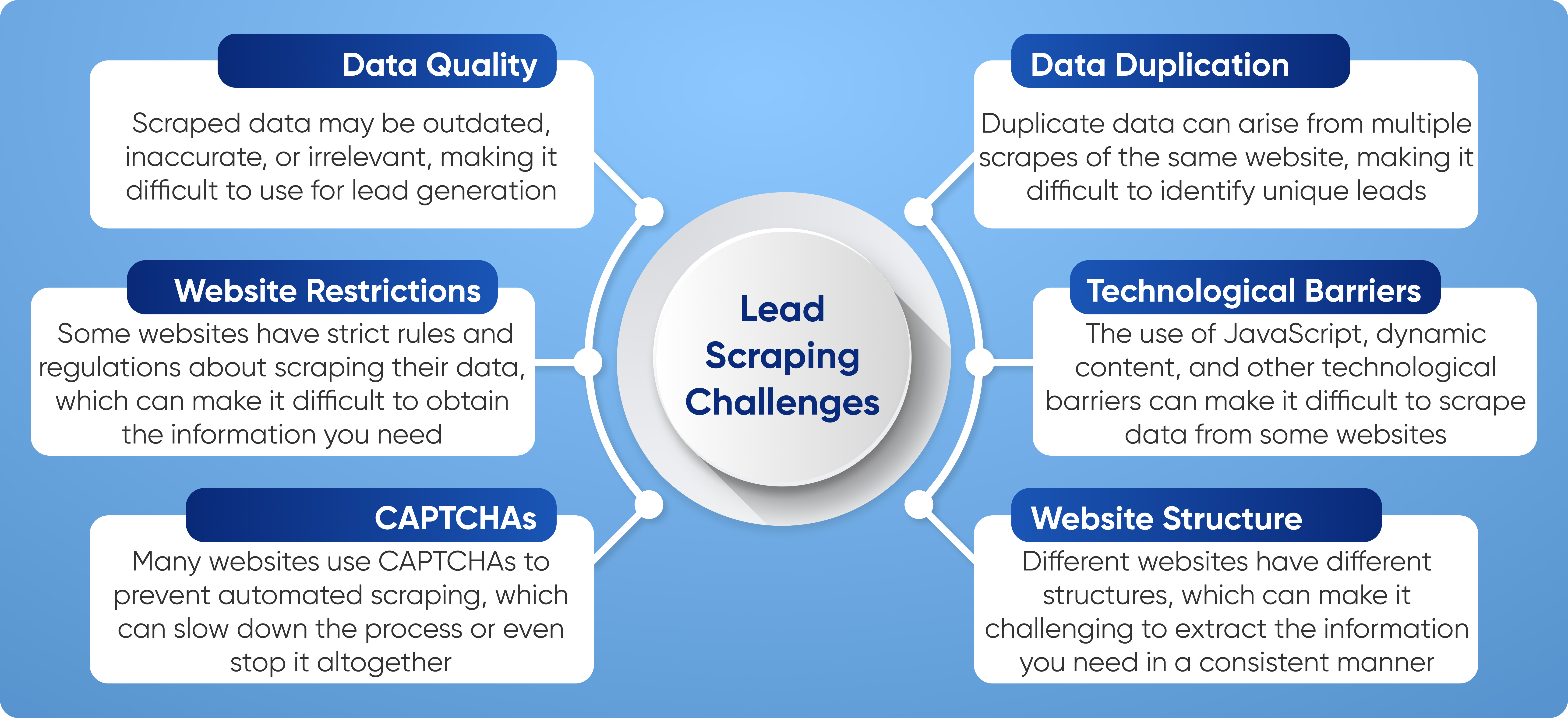
4 Web Creeping Models Web Scratching With Python, Second Version Book It retrieves the HTML pages, analyzes them using the Cheerio Node.js library and also lets you draw out any type of data from them. Internet scratching is the art of leveraging the power of automation to open the internet and essence structured web information at scale. The information accumulated can after that be made use of for many applications, such as training machine discovering formulas, cost surveillance, marketing research, lead generation, and also much more. To do this, you'll construct a web scrape to remove rate info from numerous web sites for this tutorial. The scrape will certainly gather all the rate information to make sure that it can be examined as well as contrasted later on. This is an excellent structure for building a price sharp service, and even a scalping crawler you can utilize to acquire items in restricted supply. There are additionally various other preferred libraries, such as Demands and also Lovely Soup, which may offer an improved programmer experience when making up HTTP demands as well as managing HTML records. If you wan to read more, you can examine this overview regarding the most effective Python HTTP client. In practice, internet spiders just go to a subset of pages depending on the spider budget plan, which can be an optimal number of pages per domain, deepness or implementation time. Collecting details from the net can be like alcohol consumption from a fire tube. There's a great deal of stuff available, and also it's not constantly clear what you need or just how you need it.
Setting Up The Job
Our data list currently contains a thesaurus including key info for every row. In the loophole we can combine any multi-step extractions right into one to develop the values in the least number of actions. The only class we required to use in this instance was.source-title since.views-field seem simply a class each row is given for styling and doesn't supply any originality. There's an intriguing web site called AllSides that has a media predisposition score table where individuals can agree or disagree with the score. I conserve almost every page and parse later when internet scratching as a security precaution. To retrieve our saved file we'll make one more function to cover reviewing the HTML back into html. Contact Us
Datahen
Email: services@datahen.com
Phone: +1 6476979191
2 Bloor St W
Toronto, Ontario, Canada M4W 3E2
Comparison And Comparison In Between Data Scraping And Also Creeping
Currently, if you save your code and run the crawler again you'll see that it does not just stop when it repeats with the initial web page of sets. In the grand plan of points it's not a substantial chunk of data, but now you recognize the process whereby you automatically locate brand-new pages to scuff. These kind of things will certainly be dealt with later when we build a lot more complex scrapers, however do not hesitate to allow me know in the comments of anything particularly you want finding out about. Presently, information is a list of thesaurus, each of which includes all the information from the tables along with the internet sites from each individual news source's web page on AllSides. On Apify Shop you can try hundreds of existing internet scratching options for free. As a following step, you can use Apify's Python API Client to access the output data from those ready-made services and then procedure it using Python's substantial collection of data control libraries.What is the distinction between information scratching as well as data crawling?
Information creeping is a more comprehensive procedure of systematically exploring and indexing data sources, while information scuffing is a much more specific procedure of extracting targeted data from those resources. Both methods can be utilized with each other to extract data from sites, data sources, or other resources.
Construct A Ü Cost-free Personalised ¥ Learning Strategy To See Our Program Suggestions Î For You
Hyperlinks to a number of different websites accompany the creeping cycle. Not just do they check out pages, however they additionally gather all the relevant details and index it at the same time. They likewise look for all links to the related web pages while doing so. Information scratching as well Professional web scraping services as information ETL Processes creeping are 2 terms that you frequently hear reciprocally. You have to limit the regularity of demands as well as only crawl allowed web pages by the site. Bright Data's Data Collector gathers public internet information in real-time. Cervello, a dynamic consulting company, used Bright Information Enthusiast to gain access to as well as accumulate a huge amount of data. They made use of an information collection agency to obtain internet information needed to acquire insights into customers and trends as well as focus on logical services for their customers. Download and install scratched information in the preferred style, such as JSON, CSV, and so on. Google index coverage record shows which web pages in your property are indexed as well as which are not.What is the difference between information scratching and also information crawling?
Data creeping is a more comprehensive process of methodically exploring and indexing information sources, while data scuffing is a more specific procedure of extracting targeted information from those resources. Both strategies can be utilized with each other to essence information from web sites, databases, or various other resources.
Social Links